
AI's Memory Problem Has a Fix: How MSA Scales to 100 Million Tokens
March 31, 2026
Evermind's Memory Sparse Attention (MSA) paper is a landmark result: a 4B parameter model with native internal memory beats 235B parameter RAG systems on long-context tasks, running 100M-token inference on just two GPUs.
Read more
Repeat Yourself: How Prompt Repetition Quietly Boosts LLM Accuracy for Free
March 28, 2026
Google Research found that simply repeating your prompt twice can significantly improve LLM accuracy without adding latency or output tokens. Here is what the paper found, why it works, and how you can use it today.
Read more
PageIndex: The Reasoning-Based RAG Engine That Thinks Before It Retrieves
March 17, 2026
Explore reasoning-based retrieval and how PageIndex challenges traditional vector RAG. Learn when to use it, its architecture, and why it works better for long structured documents.
Read more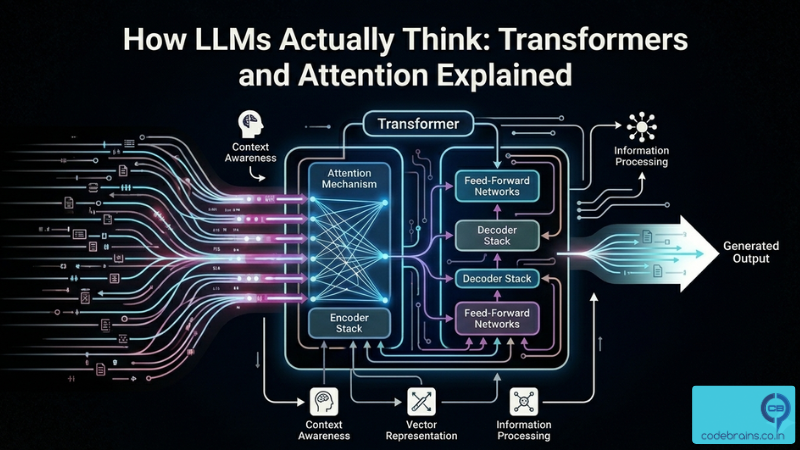
How LLMs Actually Think: Transformers and Attention Explained
February 10, 2026
Understand how transformers actually work without the math overload. Learn why RNNs failed, how attention replaced them, and how the transformer block is assembled.
Read more
Prompt Caching: The Secret to 10x Faster LLM Responses
February 10, 2026
Prompt Caching: The Secret to 10x Faster LLM Responses
Read more
The Same Trick That Made Transformers Great Just Made Them Better
February 10, 2026
Residual connections have been in every transformer since 2017. The Kimi team just found a smarter way to do them. Learn how Attention Residuals fix signal dilution across depth and reach the same model performance at 1.25x less compute.
Read more
When Attention Becomes a Bottleneck: How Mamba Is Rethinking Long-Context AI
February 10, 2026
Transformer attention scales quadratically. Learn how Mamba and state space models solve the long context problem and what it means for your AI architecture.
Read more
When AEM Meets AI: How Model Context Protocol is Turning Content Management into a Conversation
February 4, 2026
When AEM Meets AI: How Model Context Protocol is Turning Content Management into a Conversation
Read more
Moltbook: When Your AI Gets a Social Life (And You're Not Invited)
February 2, 2026
Moltbook: When Your AI Gets a Social Life (And You're Not Invited)
Read more