How LLMs Actually Think: Transformers and Attention Explained
You have been using LLMs for a while now. You know they’re “transformer-based.” You have probably seen the phrase “attention is all you need” tossed around in every AI article on the internet. But if someone asked you right now, at a whiteboard, to explain how a transformer actually works, could you do it?
If the answer is “sort of, maybe, not really” — this post is for you.
You do not need to become a machine learning researcher to reason clearly about LLM behavior. But you do need a working mental model of what is happening inside these systems. Otherwise, when something goes wrong (wrong outputs, context confusion, degraded performance at scale), you are guessing instead of diagnosing.
This is the first post in a three-part series on how LLMs actually think. We start with the foundation: transformers and attention. By the end of this post, you should be able to explain to a colleague why attention was a genuine breakthrough, not just a trendy paper title. Let’s start at the beginning, with the problem transformers were built to solve.
The Problem: Why RNNs and LSTMs Could Not Scale
Before transformers, the dominant architecture for processing sequences of text was the Recurrent Neural Network, or RNN. The idea made intuitive sense: to understand a sentence, read it word by word, carrying forward a running summary of what you have read so far.
Think of it like a game of telephone. The first person whispers the original message to the next person, who passes it along, and so on down the line. By the time it reaches the last person, the message is garbled. The further you get from the source, the more information gets lost or distorted.
RNNs had exactly this problem. They processed tokens sequentially, and the “memory” of early tokens degraded as the sequence grew longer. If you wanted the model to connect a pronoun in sentence 20 to the noun it referred to in sentence 2, you were hoping the relevant information survived eighteen steps of compression. Often it did not.
LSTMs (Long Short-Term Memory networks) were a serious attempt to fix this. They added gating mechanisms that let the model decide what to remember and what to forget. Better, but still fundamentally sequential. And sequential processing has a brutal consequence: you cannot parallelize it.
Each step depends on the previous one. You cannot split the work across GPUs meaningfully. As sequences got longer and datasets got bigger, this became a hard ceiling on scale. The models that would eventually become GPT and LLaMA simply could not have been trained on RNN or LSTM architectures. The compute would have been impossibly slow.
Transformers broke that ceiling entirely.
Tokens and Embeddings: Turning Words into Math
Before a transformer can do anything, it needs to convert text into numbers. Computers do not understand words. They understand vectors.
The first step is tokenization: splitting your input text into chunks called tokens. Tokens are not necessarily whole words. “unhelpful” might become [“un”, “help”, “ful”]. Common words stay whole; rare words get split. A typical LLM works with a vocabulary of roughly 50,000 to 100,000 tokens.
Once you have tokens, each one gets mapped to a vector embedding: a long list of floating-point numbers, often 768, 1024, or 4096 values long depending on the model. Think of it as a coordinate in a high-dimensional space where meaning lives.
The key insight is that these vectors encode semantic relationships. Words that are conceptually similar end up close together in this space. “King” minus “man” plus “woman” lands near “queen” — not because someone hand-coded that, but because the model learned it from patterns in data.
These embeddings are the raw material the transformer operates on. Every subsequent step manipulates and enriches these vectors.
When Does Tokenization and Embedding Actually Happen?
This is a question worth answering precisely, because the answer is: both during training and during every inference call. They are not the same thing, even though the same steps are involved.
During training, the embedding layer starts as random vectors. Every time the model sees a token in the training data, it looks up that token’s vector, uses it in the forward pass, and then adjusts it slightly through backpropagation. Over trillions of training tokens, the embedding vectors get shaped to reflect meaning. By the end of training, “Paris” and “France” are close in vector space, “cat” and “kitten” are close, and “king” minus “man” plus “woman” lands near “queen.” None of this was hand-coded. The model learned it from patterns in data.
During inference (when you send a prompt), the embedding layer is frozen. Those weights were fixed at the end of training. But the tokenization and embedding steps still run — they run fresh for every request, right at the start of processing. Your prompt gets split into tokens, each token gets looked up in the frozen embedding table, and the resulting vectors are what flows into Block 1 of the transformer.
A useful way to think about it: training answers “what should each token’s vector look like?” Inference uses those answers to convert your specific input into vectors and start processing. The lookup happens at runtime, every time, but the meaning encoded in those vectors was baked in during training.
This is also why LLMs can struggle with tokens they rarely saw during training. If a technical term, a product name, or a recently coined word appeared very infrequently in the training corpus, its embedding is less well-calibrated. The vector exists, but it does not carry much signal. The model has less to work with.
But here is a problem: transformers process all tokens in parallel. They have no inherent sense of order. If you feed it the words “dog bites man” and “man bites dog,” the embeddings alone do not tell the model which came first. This is where positional encoding comes in.
Each token’s embedding gets a positional signal added to it, encoding its index in the sequence. Position 1 gets one pattern, position 2 gets a slightly different one, and so on. Now the model can distinguish order, even though it processes everything simultaneously.
Self-Attention: The Core Insight
This is the part that matters most. Everything else in the transformer is scaffolding. Attention is the engine.
The idea is deceptively simple: when processing each token, the model decides which other tokens in the sequence are relevant to it, and blends information from those tokens accordingly.
To do this, the transformer projects each token’s embedding into three different vectors: a Query (Q), a Key (K), and a Value (V). Here is the engineering analogy that makes this click:
Imagine you are searching a database. Your Query is your search term (“what am I looking for?”). Each document in the database has a Key, which is its label or index (“what is this document about?”). The Value is the actual content of the document (“what does this document say?”).
When you run a search, you compare your Query against all the Keys to figure out which documents are relevant. Then you retrieve the Values from those documents, weighted by how relevant they were. That is exactly what attention does, except every token simultaneously acts as both searcher and document.
Concretely: when processing the word “it” in the sentence “The trophy did not fit in the suitcase because it was too big,” the model’s Query for “it” gets compared against the Keys of every other token. The Keys for “trophy” and “suitcase” should score high, and the Values from those tokens flow back to enrich the representation of “it.” The model learns that “it” refers to the trophy, not the suitcase — not by a rule, but because attention found the relevant context.
This is why attention was such a breakthrough. Every token can directly attend to every other token in a single step. There is no telephone game. No degrading chain of handoffs. Token 1 and token 500 have exactly the same direct connection as two adjacent tokens.
Multi-Head Attention: Multiple Perspectives at Once
A single attention pass gives you one perspective on relevance. But language is layered. In the sentence “The bank by the river had steep slopes,” the word “bank” needs to track its relationship to “river” (geographic context) and possibly to grammatical subject structure simultaneously.
Multi-head attention runs several independent attention passes in parallel, each with its own learned Q, K, V projection matrices. Each “head” can specialize in a different type of relationship: one might track syntactic dependencies, another coreference (pronouns pointing to nouns), another semantic similarity.
Think of it like a document going through a team of reviewers simultaneously. One reviewer checks for logical consistency, another checks for tone, another checks for technical accuracy. Each brings back their own set of notes. At the end, all their notes get merged into a single enriched understanding of the document.
In practice, a model like GPT-3 uses 96 attention heads per layer. That is 96 simultaneous perspectives on every token in your input, at every layer of the network.
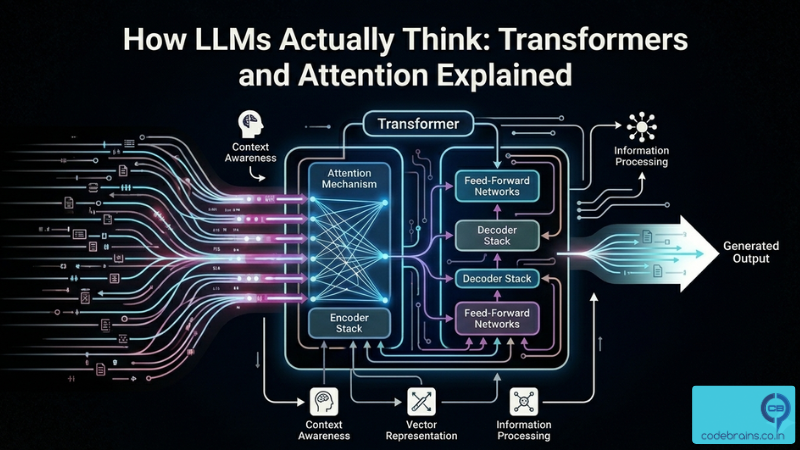
The Transformer Block: Putting It All Together
A transformer is not just attention. It is a repeating stack of blocks, each one refining the token representations a little more. Here is what lives inside a single transformer block:
1. Multi-head self-attention. Tokens attend to each other and blend in contextual information. This is where relationships are captured.
2. Feed-forward network. After attention, each token’s representation passes through a small, independent neural network. This is where the model applies learned transformations to individual token representations. Think of it as each token “digesting” the context it just gathered and deciding what to keep.
3. Residual connections. Before and after both of the above, the original input is added back to the output. This sounds trivial but is crucial: it prevents gradients from vanishing during training and lets the model “pass through” information unchanged when needed. If the attention step learned nothing useful, the residual connection ensures the signal is not lost.
4. Layer normalization. After each sub-step, the values are normalized to keep them in a stable numerical range. This stabilizes training and makes the whole stack of layers behave more predictably.
The transformer block is the repeating layer of the model. When people say a model has 96 layers, they mean 96 of these blocks stacked on top of each other. One block in, one block out. The output of Block 1 becomes the input to Block 2. The output of Block 2 becomes the input to Block 3. And so on, all the way to Block 96.
Every block has the same structure, but each one has its own independently learned weights. So Block 1 is not doing the same computation as Block 50 — they have both learned to do different things at different levels of abstraction. Early layers tend to capture low-level patterns like grammar and word order. Middle layers pick up semantic relationships. Later layers encode the abstract reasoning the model needs for the task at hand.
By the time you reach the final block, the token representations have been through dozens of rounds of attention and feed-forward refinement. They are extraordinarily rich compared to the raw embeddings that entered Block 1, encoding complex relationships that simple word vectors could never capture.
Decoder-Only: Why Modern LLMs Are Built the Way They Are
The original transformer paper (“Attention Is All You Need,” 2017) described an encoder-decoder architecture. The encoder reads the input and builds rich representations. The decoder generates the output, attending to both its own prior tokens and the encoder’s representations. This design made sense for tasks like translation, where input and output are separate sequences.
But GPT, LLaMA, Claude, and most modern LLMs use a decoder-only architecture. There is no separate encoder. There is just one transformer stack, generating tokens one at a time, left to right.
The key mechanism that makes this work is causal masking. When generating token N, the model can attend to tokens 1 through N-1, but not to any future tokens. This is enforced by masking out those positions in the attention matrix. The model never “cheats” by looking ahead.
Why decoder-only over encoder-decoder? A few reasons. It is simpler, which means easier to scale. It handles open-ended generation naturally since you just keep producing tokens until done. And in practice, very large decoder-only models turn out to be excellent at “encoding” tasks too, like reading comprehension and classification, just by framing them as text generation problems.
When you ask an LLM a question, it is not running a search. It is autoregressively generating the most probable next token, then using that token as input to generate the next one, and so on. The entire answer is produced one token at a time, each step conditioned on everything before it.
The One Limitation You Need to Know: Quadratic Attention
Attention is powerful, but it comes with a cost that every engineer building on top of LLMs needs to understand.
When computing attention, every token compares itself against every other token. If you have N tokens in your sequence, that is N x N comparisons. Attention scales quadratically with sequence length.
Double your context window, and you quadruple the compute for attention. A sequence of 1,000 tokens requires 1 million comparisons. A sequence of 100,000 tokens requires 10 billion comparisons. This is not a constant-factor overhead. It is a fundamental architectural constraint.
This is why context windows were stuck at 2K or 4K tokens for years. It is why extending to 128K or 1M tokens requires genuine engineering innovation, not just more compute. Techniques like sparse attention, sliding window attention, and linear attention approximations all exist precisely to work around this quadratic wall.
It is also why the economics of inference change so dramatically as context grows. A 128K-token context does not cost 32x a 4K-token context in a linear sense. The math is worse than that.
Understanding the quadratic nature of attention is table stakes for reasoning about LLM performance, cost, and the engineering tradeoffs you will make when building systems on top of them. In the next post in this series, we will explore how the industry is tackling the context length challenge, and what the different approaches mean for your architecture.
Key Takeaways
Here is what you should walk away with:
RNNs broke because they were sequential. No parallelism, information bottleneck, vanishing gradients. Transformers replaced the sequential chain with direct attention between all tokens. Tokenization and embedding happen both during training and during inference. Training shapes what the vectors mean. Inference uses those frozen vectors to convert your prompt at runtime. The lookup happens fresh every request — but the meaning encoded in those vectors was baked in over trillions of training tokens.
The transformer block is the repeating layer of the model. Stack 96 of them and you have GPT-3. Each block has the same structure but its own learned weights. Early layers capture grammar, middle layers capture semantics, later layers handle abstract reasoning.
Attention is a learned search. Each token’s Query gets compared against all other tokens’ Keys. The tokens with matching Keys contribute their Values. Every token gets a contextually enriched representation. Multi-head attention runs several of these passes simultaneously. Different heads specialize in different types of relationships. Together they capture language’s full complexity.
A transformer block stacks attention, feed-forward, residuals, and normalization. Modern LLMs repeat this block dozens to hundreds of times. Each layer deepens the model’s understanding. Modern LLMs are decoder-only. They generate one token at a time, attending only to past context, masked from the future.
Attention is quadratic. This is the fundamental constraint that shapes context window limits, inference cost, and a whole generation of research into making attention more efficient — including entirely new architectures like Mamba.
You now have the mental model to reason about why LLMs behave the way they do: why they handle nearby context better than distant context, why very long prompts are expensive, why they generate token by token rather than all at once. The architecture explains the behavior.
In the next post in this series, we will explore how the industry is tackling the context length challenge, and what the different approaches mean for your architecture.
Got questions, or running into LLM behaviors that make more sense now? I would love to hear about it. Connect with me on LinkedIn.